이전 포스팅에서 RStudio 설치 및 기본 함수 사용법, 패키지 등에 대해서 살펴보았습니다.
이번 포스팅에서는 문자로 된 데이터에서 가치 있는 정보를 얻어 내는 분석 기법인 '텍스트 마이닝' 방법에 대해 살펴보겠습니다.
텍스트 마이닝(Text Mining)을 하기 위해서 가장 먼저 해야 하는 일은 바로 문장을 구성하는 품사들을 파악하는 '형태소 분석(Morphology Analusis)'입니다.
형태소 분석을 통해 어절들의 품사를 파악하여 명사, 동사, 형용사 등 의미를 가진 단어들을 추출하고 각 단어들이 얼마나 많이 등장했는지 확인하게 됩니다. 이후 빈도표를 만들어서 이를 시각화 하면 분석하고자 하는 문서에 대한 유의미한 트렌드를 확인할 수 있습니다.
텍스트 마이닝을 하기 위해서는 먼저 패키지들을 설치해야 하는데
우리가 사용할 패키지는 한글 자연어 분석 패키지인 KoNLP(Korean Natural Language Processing)입니다.
KoNLP를 사용하기 위해서는 몇 가지 패키지를 설치해야 하는데 패키지 설치시 여러가지 오류가 발생할 수 있기 때문에 이와 관련해서는 별도의 포스팅을 올려두었습니다. (설치 관련 포스팅 바로가기)
설치관련 간단히 절차를 요약해 보자면
먼저 내 컴퓨터에 Java 실행 환경을 구성해 주는 JRE 패키지를 별도로 설치한 후에 시스템 환경변수를 잡아주고
RTools를 다운받아 설치해 주어야 합니다.
그리고 RStudio에서는 rJava 패키지와 memoise 패키지, multilinguer 패키지를 설치해주고
의존성 패키지인 stringr, hash, tau, Sejong, RSQLite, devtools를 바이너리 Type으로 설치해줘야 합니다.
KoNLP 패키지는 깃허브와 연동하여 설치를 진행하는데 이를 위해서 remotes 패키지를 설치해주고
아래와 같이 RStudio에서 KoNLP 패키지를 설치합니다.
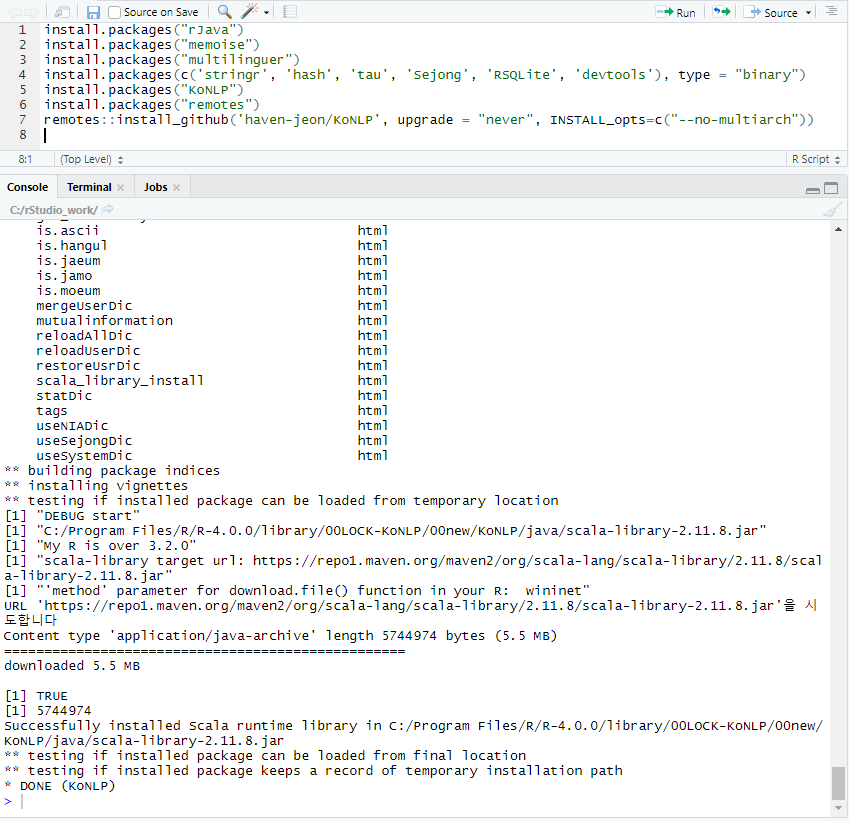
위 그림과 같이 패키지 설치가 성공적으로 끝나면 KoNLP와 전처리 작업에 사용할 dplyr를 로드하여 준비를 마칩니다.
물론 dplyr 패키지도 설치가 되어 있어야 library 로드가 가능합니다.
이제 텍스트 마이닝을 위한 RStudio 세팅이 끝났습니다.
본격적으로 텍스트 마이닝을 시작하기에 앞서 우리가 관심있게 분석해야 할 문서 데이터를 준비해야겠지요.
저는 최근 청와대 국민청원 게시판에 올라온 분야별 청원 게시글의 제목들만 발췌하여 이 시대를 살아가는 국민들이 어떤 어려움을 겪고 있는지 텍스트 마이닝을 통해 분석해 보았습니다.
텍스트 문서는 일반 txt 형태의 문서로 만들고 파일 이름은 sample.txt로 생성하였습니다.
텍스트 문서 분석을 위해서 사전 전처리 과정이 필요한데 저는 청원 게시판의 카테고리와 날짜 등은 제외시키고 새로운 sample1.txt로 재편집하였습니다.
RStudio에서 아래와 같이 로드합니다.

한글 txt 파일을 로드해서 콘솔에 출력해 보니 한글이 깨져있습니다.
RStudio에서 바로 파일을 더블클릭해 보면 아래와 같이 정상적으로 로딩이 되는데 유독 콘솔에서만 한글이 깨진다면 인코딩에 문제가 있기 때문입니다.

이 문제는 한글파일에서 UTF-8 형태로 저장은 되어 있지만 UTF-8 인코딩에 BOM(Byte Ordr Mark)이 포함되어 있어서RStudio의 인코딩을 UTF-8로 변경하여도 콘솔에서 깨져서 출력되기도 합니다.
이를 해결하기 위해서는 먼저 콘솔에 아래와 같이 options(encoding = "UTF-8")로 적용해 주고 한글문서에서도 저장시 BOM을 제거하여 새롭게 저장한 후 다시 RStudio에서 로딩해줍니다. 아래와 같이 콘솔에 정상 출력되는 것을 확인하실 수 있습니다.

이제 KoNLP에서 제공하는 사전을 설정하고 아래 이미지 순서대로 텍스트 마이닝을 위한 명사 추출, 빈도표 데이터프레임 생성, 두 글자 이상 단어를 추출해 보겠습니다.
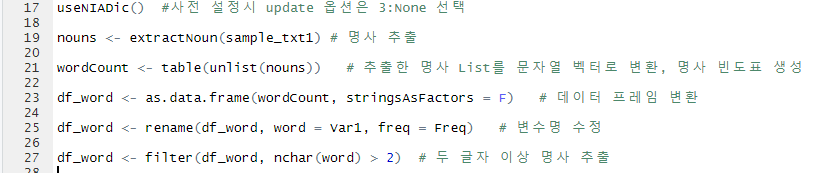
실행문 우측의 '#' 기호는 주석기호로 실행문을 설명해 주고 있습니다.
이제 워드 클라우드를 만들기 위해서 다시 패키지를 준비합니다.
install.packages("wordcloud")
library(wordcloud)
library(RColorBrewer)
워드 클라우드 패키지를 설치하고 로딩이 끝나면 아래와 같이 단어별 색상 목록으로 추출하기 위해 팔래트를 구성해 줍니다.
pal <- brewer.pal(8, "Dark2") # Dark2 색상 목록 중 8개 색상 추출
set.seed(1234) # 난수 고정
최종적으로 아래와 같이 wordcloud( ) 함수에 인자를 넣어서 실행하면 워드 클라우드를 출력할 수 있습니다.
wordcloud(words = df_word$word, freq = df_word$freq, min.freq = 2, max.words = 100, random.order = F,
rot.per = .1, scale = c(4, 0.3), colors = pal)
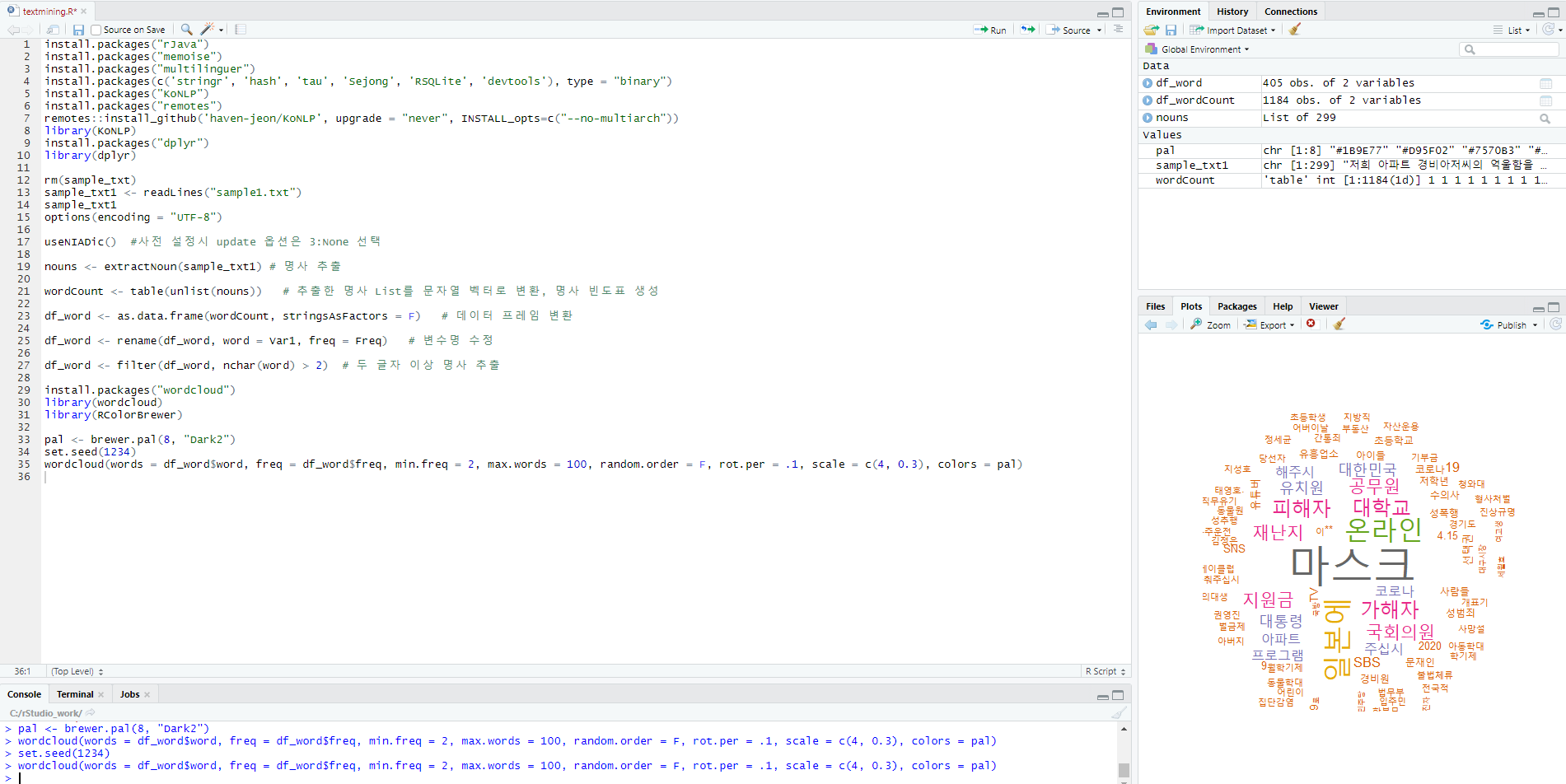
실제 워드클라우드를 확대해서 분석해 보면
코로나 19의 영향으로 코로나 이슈 관련 트렌드 키워드가 청원의 주를 이루고 있음을 알 수 있습니다.

감사합니다.
'데이타베이스' 카테고리의 다른 글
| SQL 고급 질의어 정리 (0) | 2020.05.23 |
|---|---|
| SQL 기본 질의어 정리 (0) | 2020.05.21 |
| MySQL Workbench 사용법 (2) | 2020.05.15 |
| R 프로그래밍[1] (0) | 2020.05.11 |
| R 프로그래밍[0] (0) | 2020.05.09 |




댓글